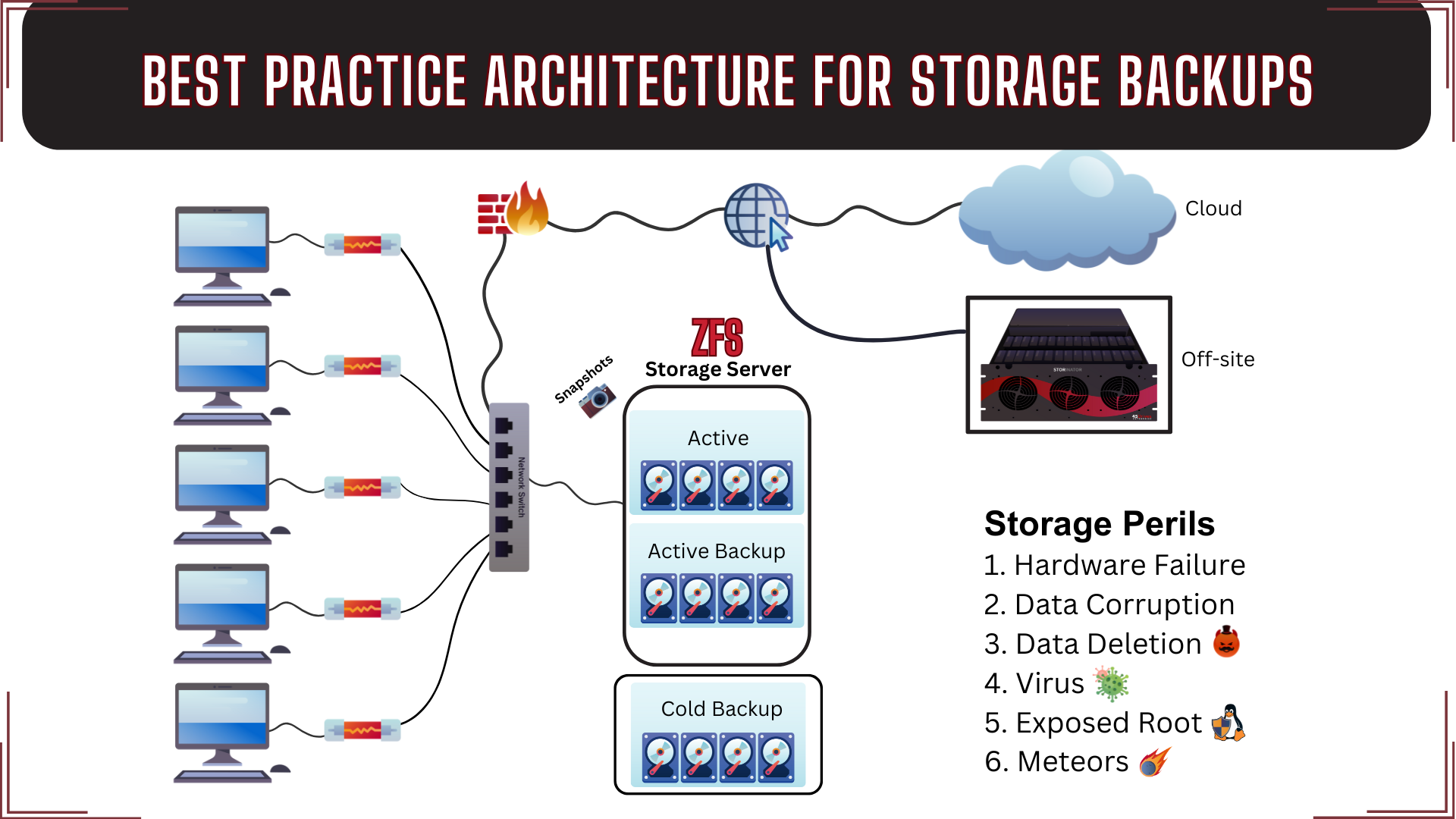
Understanding Snapshots
File system backup or snapshots, how do you know which one to choose? If you’re unfamiliar with backups – here’s a refresher. Backups are essentially backing up all your data onto another server. This means if one server fails you have all your data saved on another. To restore your data, it may take a little time as these are read and write. But today I want to talk more about Snapshots as there has been a little confusion over when to use this tool.
In this blog, I want to help you understand filesystem snapshots, their benefits, and their limitations. I hope by the end of this short blog you’ll have a better understanding of snapshots and when to use them. So, what are snapshots?
Snapshots
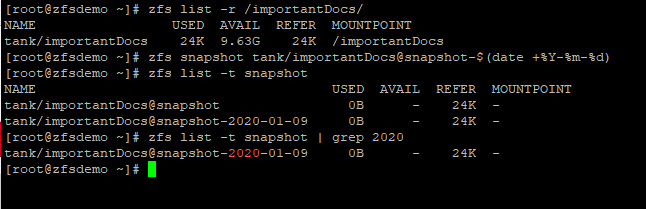
Snapshots are powerful tools you can leverage for file recovery and increased backup efficiency. Snapshots save your files exactly how it looked at a specific point in time, giving you the ability to roll back to previous states as required. Keep in mind, snapshots don’t actually save any data – they define where and how data was organized at that time. Snapshots hold onto deleted data that wouldn’t be accessible through the live file-system, which is why they initially take up no space but can balloon.
In general terms, a snapshot of your files is, exactly as it sounds, a picture of the state of your files at some point in history. Think “Wayback Machine” for finding old internet pages.
Snapshots are most often used to roll back entire file-systems or pull specific files that were accidentally deleted or corrupted. Both tasks that would initially be thought of as something a backup would be used for, and they are both tasks snapshots can usually do better than backups. That is likely why some people confuse snapshots with backups. Snapshots are not backups.
Snapshots are achieved through different methods depending on your OS/file-system. But the key constant for snapshots across systems is that they are not a replacement for real backups. Snapshots exist as part of your storage pool if anything happens that damages the pool, the snapshot will be damaged too. It is analogous to putting files on a USB drive twice. If you break the drive it doesn’t matter how many copies of your data you have on it, that data is still gone.
Snapshots do benefit the process of taking backups. Snapshots allow you to incrementally backup your data. They remember how a server was and what was changed, you can simply copy over the changes and ignore the rest. For example, you could replicate the entire pool onto another server in a different location, then each day after that only copy the changes since the previous day.
Snapshots also ensure your backups will be time-consistent. If you take a backup on live data, there is a chance that the data will diverge over the course of the backup. Imagine a file someone is working on while the system is being backed up. If the system is halfway through backing the file up when the user saves it, it could be corrupted on the backup. Snapshots solve this by allowing the system to take the backup on an imaged version of your data from a specific point in time. If the user modifies a file while the backup is taking place, it will simply save the unmodified version.
Conclusion
Snapshots are great tools, but remember if something happens that destroys or corrupts your entire pool, your snapshots will be destroyed along with the rest of it.If your data is sensitive, the only way to ensure your organization will survive catastrophe is by having a disaster recovery solution in place.
Snapshots are for recovering from errors made by human users, like accidental file deletions or overwriting the wrong file. Backups are for recovering from hardware errors by faulty components or environmental such as fire or the ever terrifying meteor strike.

Check out our article on Disaster Recovery vs. High Availability, or if you want to get in contact reach out to one of our account managers.